import pandas as pd
import numpy as np
import pickle as pk
import streamlit as st
model=pk.load(open(‘model.pk1′,’rb’))
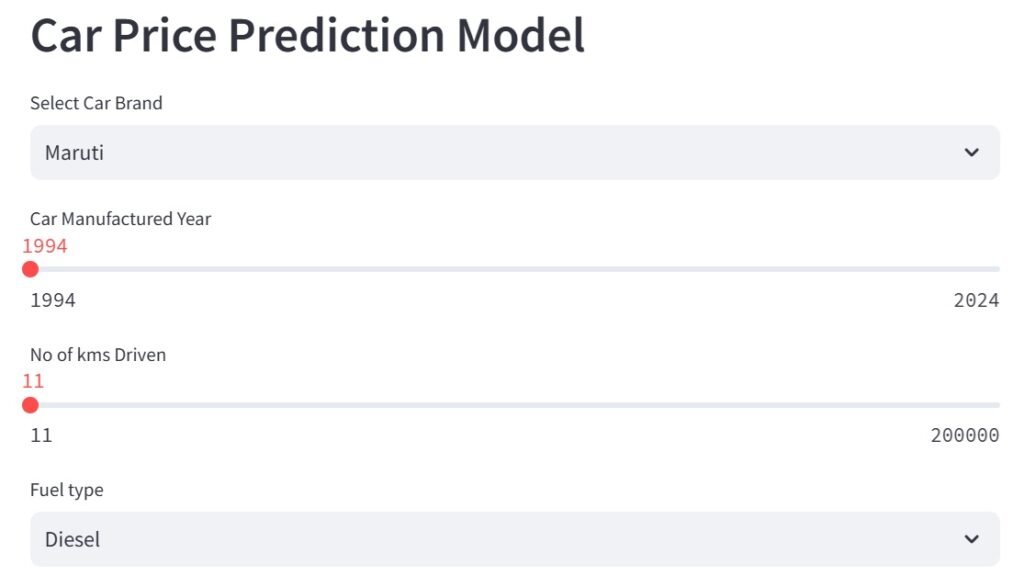
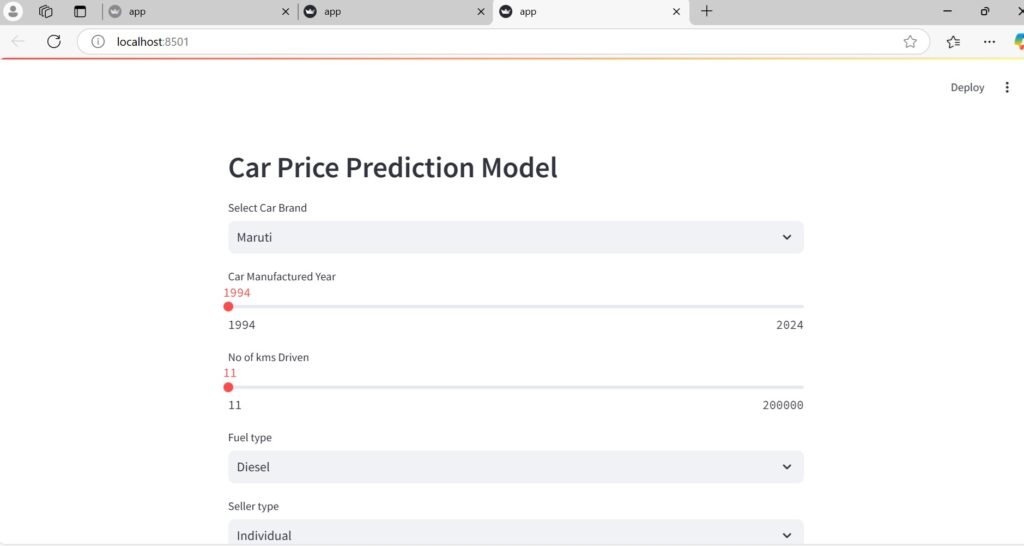
st.header(‘ Car Price Prediction Model ‘)
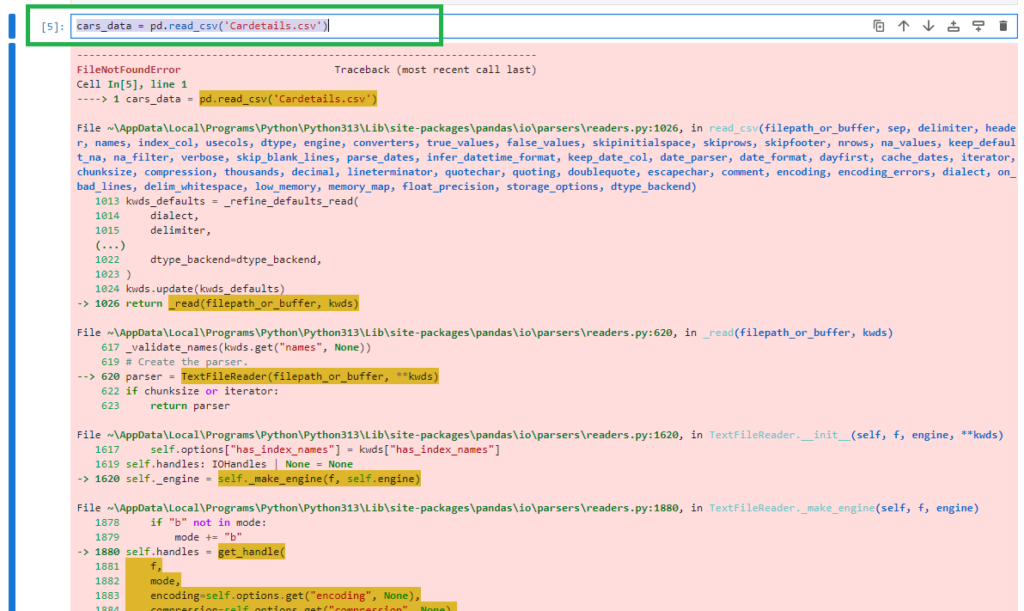
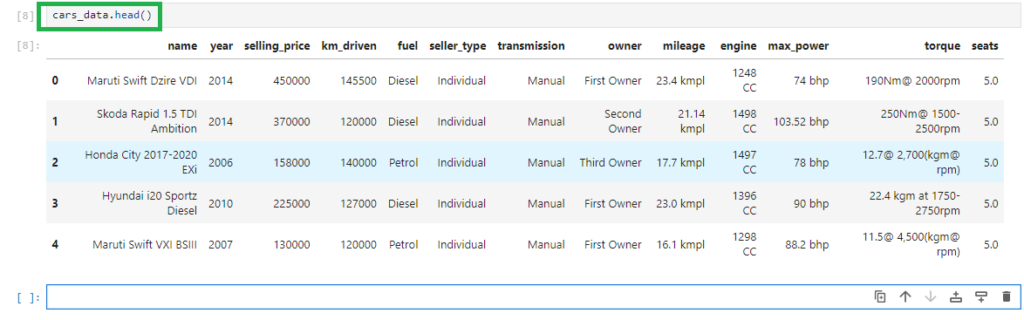
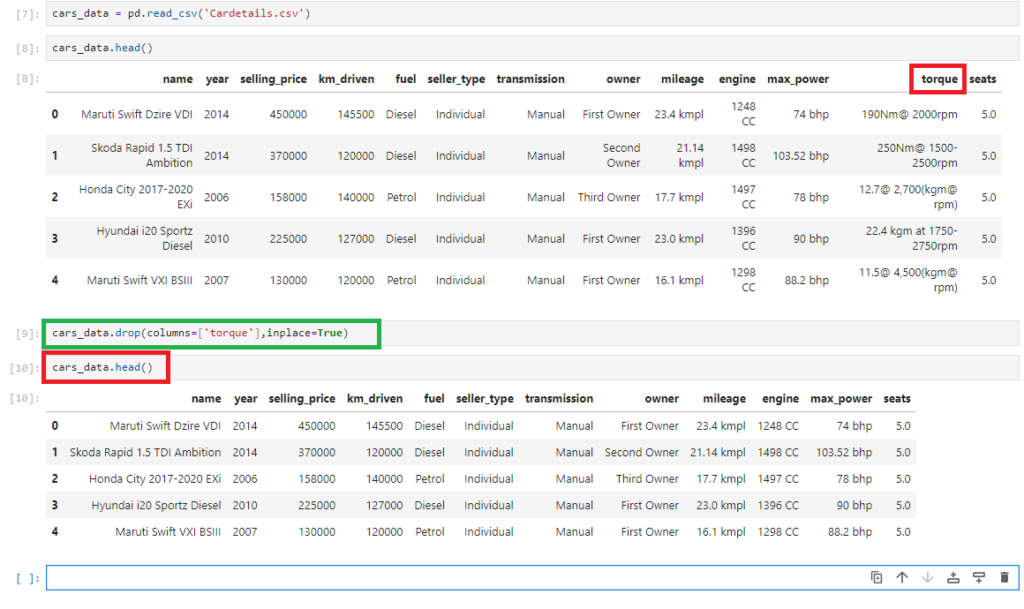
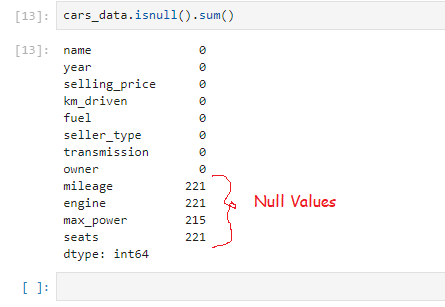
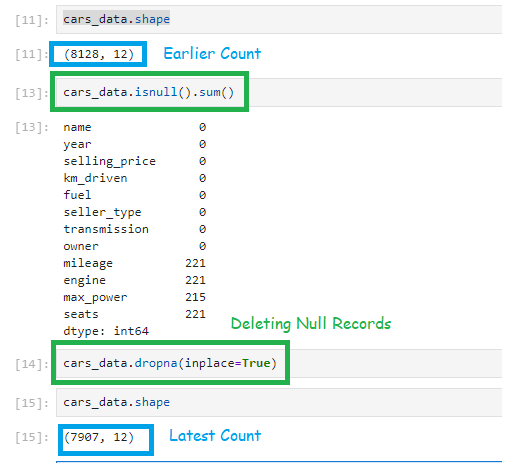
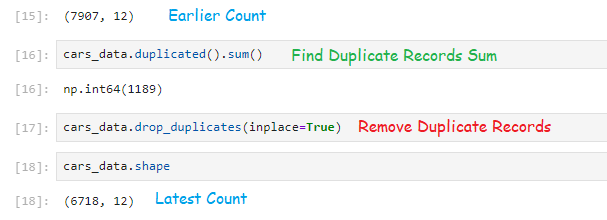
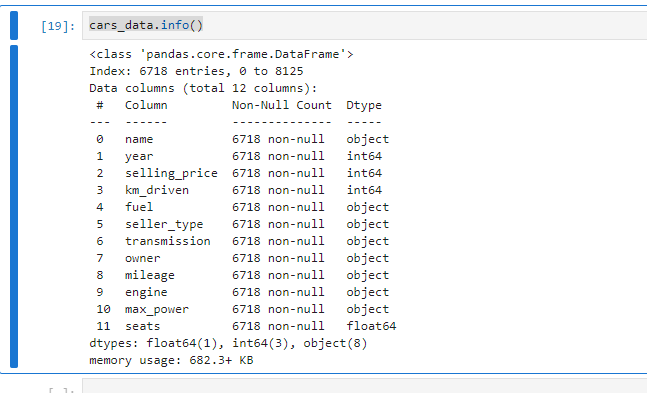
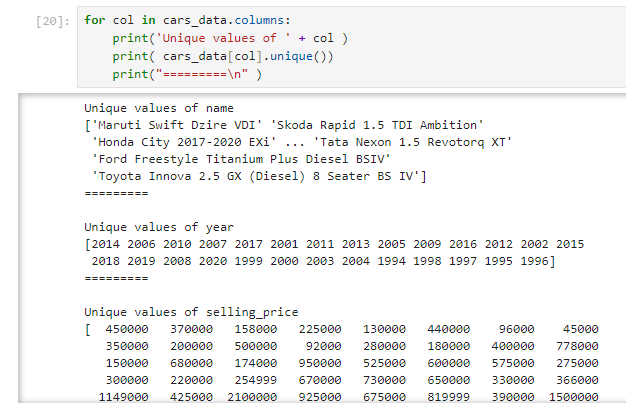
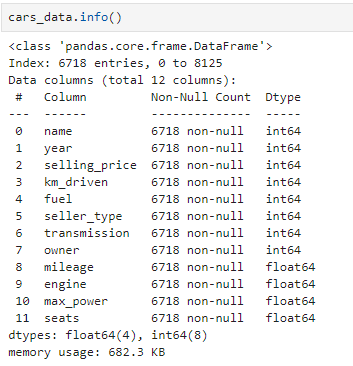
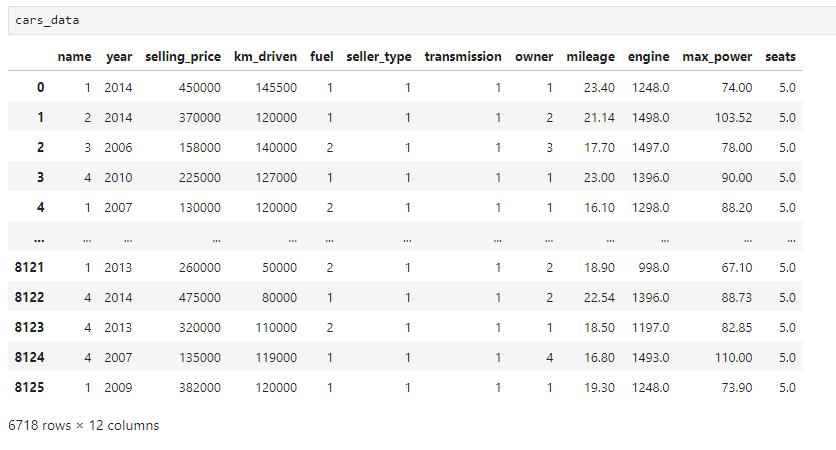
cars_data = pd.read_csv(‘Cardetails.csv’)
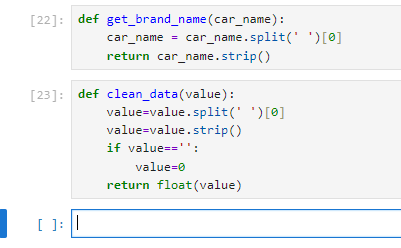
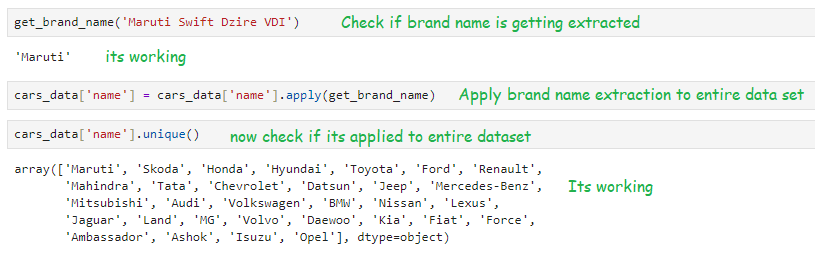
def get_brand_name(car_name):
car_name = car_name.split(‘ ‘)[0]
return car_name.strip()
cars_data[‘name’] = cars_data[‘name’].apply(get_brand_name)
name = st.selectbox(‘Select Car Brand’, cars_data[‘name’].unique())
year = st.slider(‘Car Manufactured Year’, 1994,2024)
km_driven = st.slider(‘No of kms Driven’, 11,200000)
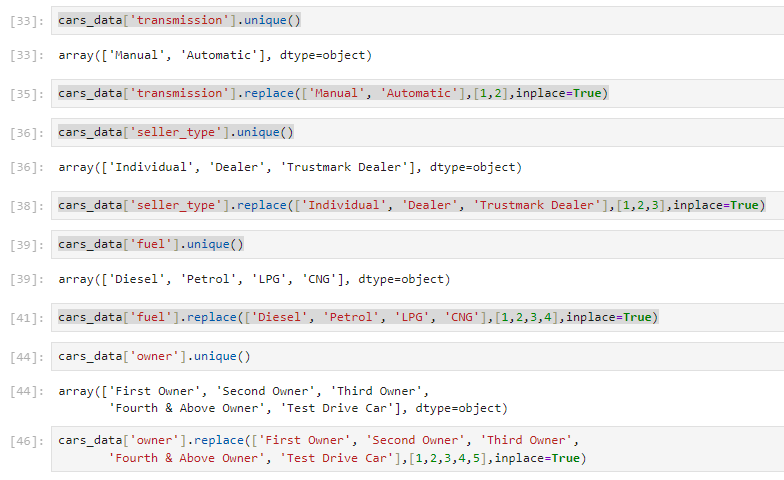
fuel = st.selectbox(‘Fuel type’, cars_data[‘fuel’].unique())
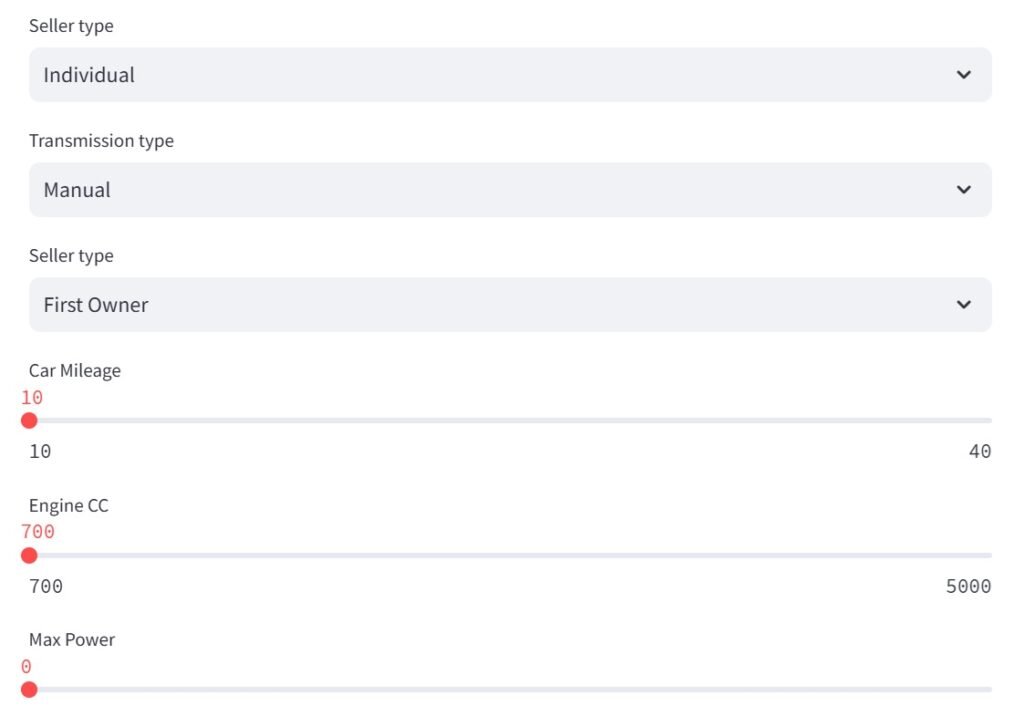
seller_type = st.selectbox(‘Seller type’, cars_data[‘seller_type’].unique())
transmission = st.selectbox(‘Transmission type’, cars_data[‘transmission’].unique())
owner = st.selectbox(‘Seller type’, cars_data[‘owner’].unique())
mileage = st.slider(‘Car Mileage’, 10,40)
engine = st.slider(‘Engine CC’, 700,5000)
max_power = st.slider(‘Max Power’, 0,200)
seats = st.slider(‘No of Seats’, 5,10)
if st.button(“Predict”):
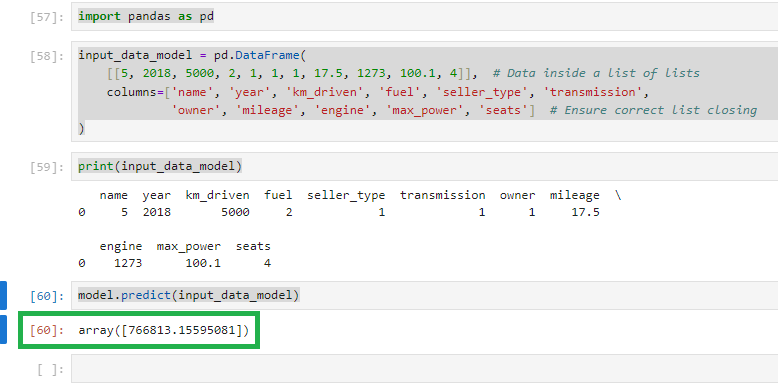
input_data_model = pd.DataFrame(
[[name,year,km_driven,fuel,seller_type,transmission,owner,mileage,engine,max_power,seats]],
columns=[‘name’,’year’,’km_driven’,’fuel’,’seller_type’,’transmission’,’owner’,’mileage’,’engine’,’max_power’,’seats’])
input_data_model[‘owner’].replace([‘First Owner’, ‘Second Owner’, ‘Third Owner’,
‘Fourth & Above Owner’, ‘Test Drive Car’],
[1,2,3,4,5], inplace=True)
input_data_model[‘fuel’].replace([‘Diesel’, ‘Petrol’, ‘LPG’, ‘CNG’],[1,2,3,4], inplace=True)
input_data_model[‘seller_type’].replace([‘Individual’, ‘Dealer’, ‘Trustmark Dealer’],[1,2,3], inplace=True)
input_data_model[‘transmission’].replace([‘Manual’, ‘Automatic’],[1,2], inplace=True)
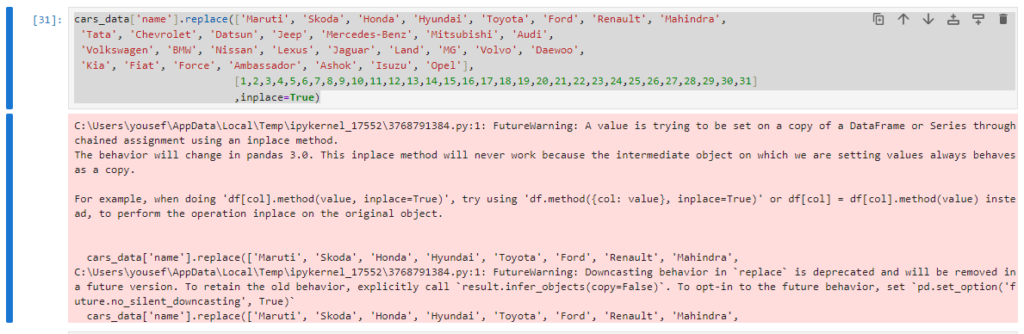
input_data_model[‘name’].replace([‘Maruti’, ‘Skoda’, ‘Honda’, ‘Hyundai’, ‘Toyota’, ‘Ford’, ‘Renault’,
‘Mahindra’, ‘Tata’, ‘Chevrolet’, ‘Datsun’, ‘Jeep’, ‘Mercedes-Benz’,
‘Mitsubishi’, ‘Audi’, ‘Volkswagen’, ‘BMW’, ‘Nissan’, ‘Lexus’,
‘Jaguar’, ‘Land’, ‘MG’, ‘Volvo’, ‘Daewoo’, ‘Kia’, ‘Fiat’, ‘Force’,
‘Ambassador’, ‘Ashok’, ‘Isuzu’, ‘Opel’],
[1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16,17,18,19,20,21,22,23,24,25,26,27,28,29,30,31]
,inplace=True)
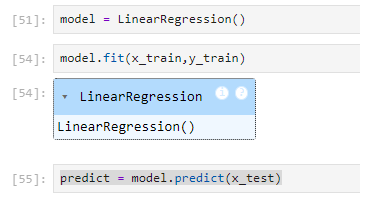
car_price = model.predict(input_data_model)
#st.markdown(‘Car Price is going to be : ‘+ str(car_price[0]))
st.markdown(‘Car Price is going to be : ‘ + str(abs(int(round(car_price[0])))))